NLP endpoints: Haystack plus FastAPI
The easy, powerful and fast combo for NLP endpoints

In this article, we will build together a FastAPI application which interacts with Haystack. It's an experiment intended to be a starting point for anyone wishing to use haystack as a service for other projects. And one of the easiest ways is through a REST API. You can deploy a REST API into a physical machine, a virtual machine, a container, or a serverless environment (like AWS Lambda or Azure Functions).
Let's code.
The virtual environment
Everybody loves Python!
Who doesn't get amazed to "talk with the code"? When coding in Python, I feel like talking to my computer. For someone coding since when I was 12yo, you may understand my passion.
Python has thousands of available modules, and each day more come up. When you need something, look for it deeper on PyPi. It's hard not to find something. But this reminds me of one of the most famous sentences in a movie: "With great power comes great responsibility." If we keep installing modules into a mixed environment, we are building the path for considerable problems in the dependency chain, testing, and organization. The recommended way is to use isolated environments, which can be achieved by python-venv.
Create a new environment.
python3 -m venv venv
Activate the virtual environment.
source venv/bin/activate
Install Haystack
Now we install the outstanding framework Haystack NLP framework.
We use OpenSearch as our Document Store. For this, we set the egg opensearch to instruct pip to install its related dependencies together with the framework.
pip install fastapi
Create an empty python file
touch app.py
The health-check endpoint
First, exposing a health-check endpoint is a good practice. But what is a health-check endpoint?
It's a route that tells external systems the current status of your application. For example, normal states are running correctly (green), partially (yellow), or not running correctly (red). Some providers can check this endpoint to know if your app is running correctly and doesn't need a restart. It's also useful by allowing you to set up alarms in monitoring tools.
from fastapi import FastAPI
app = FastAPI()
@app.get("/health")
def health():
return {"status": "ok"}
This code isn't doing extended checks and returning possible warnings (yellow reasons) or errors (red reasons). But a production API really should. It's a starting point, and what it should return when not working is tightened to each application and business.
Async capabilities
Besides using a usual definition, which is synchronous, FastAPI also supports asynchronous methods. In IO-heavy applications, asynchronous code is critical to avoid bottlenecks and improve performance. Therefore, you need to add async into your method definition.
from fastapi import FastAPI
app = FastAPI()
@app.get("/health")
async def health():
return {"status": "ok"}
Running your FastAPI application
Ok, you may be thinking now about how you run this application. Probably, you are considering calling "python app.py", right? But, no, FastAPI is a framework, not a server. Therefore, you must use something else. Here is where uvicorn is helpful. There is also gunicorn, a WSGY server, but this is for another article.
Install it.
pip install uvicorn[standard]
From the command line, you can now run:
uvicorn app:app --reload --workers 1
The first app is the python filename without the extension, and the second is the FastAPI App object. The reload option will make uvicorn reload the file whenever it's changed. Use this only when developing if you like real-time updates.
It will start at the default port, 8000. So you should see on the command line something like:
INFO: Will watch for changes in these directories: ['/home/danielbichuetti/Dev/Projects/fastapi_haystack']
INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
INFO: Started reloader process [57303] using WatchFiles
INFO: Started server process [57307]
INFO: Waiting for application startup.
INFO: Application startup complete.
Testing the skeleton application
curl http://localhost:8000/health
The response must be:
{"status":"ok"}
Yeah, it's a JSON string. Pretty easy to build a REST API, right? It's just a tiny amount of FastAPI power. It's straightforward and fast.
Deploy an OpenSearch cluster
Do you have any OpenSearch servers available? If yes, you can jump to the next section. If not, you will love this one.
Create an AWS OpenSearch Service
Go to AWS console portal and log in. If you are not a user yet, please sign up for a free account.
They provide Amazon OpenSearch Service on their free tier. So yeah, 750 hours of t3.small.search instance monthly. It's a good starting point.
After you have logged in, find Amazon OpenSearch Service. Then click on Create Domain

You will get redirected to the cluster creation screen. The first field is the name you want to use for your cluster. Let's call it haystack.
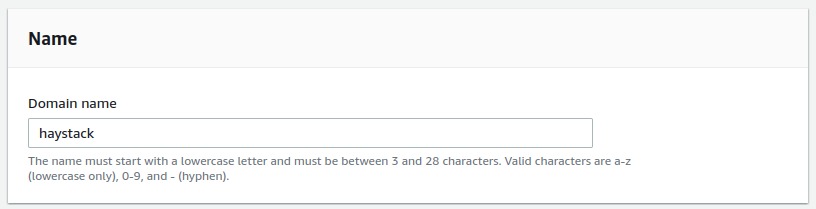
Choose the Deployment type, Development and testing, and select 1.3 (latest) as the version.
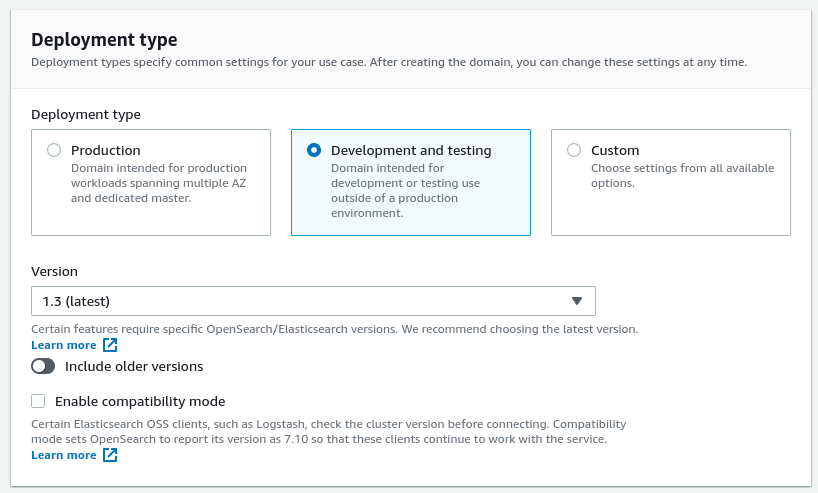
Let's tweak some default Data nodes options to keep setup simple and use just the free tier. First, let's use only 1 AZ, and change the Number of nodes to 1. On Instance Type, change to t3.small.search. Don't change the EBS size to more than 20GB, as it's the maximum allowed for free.
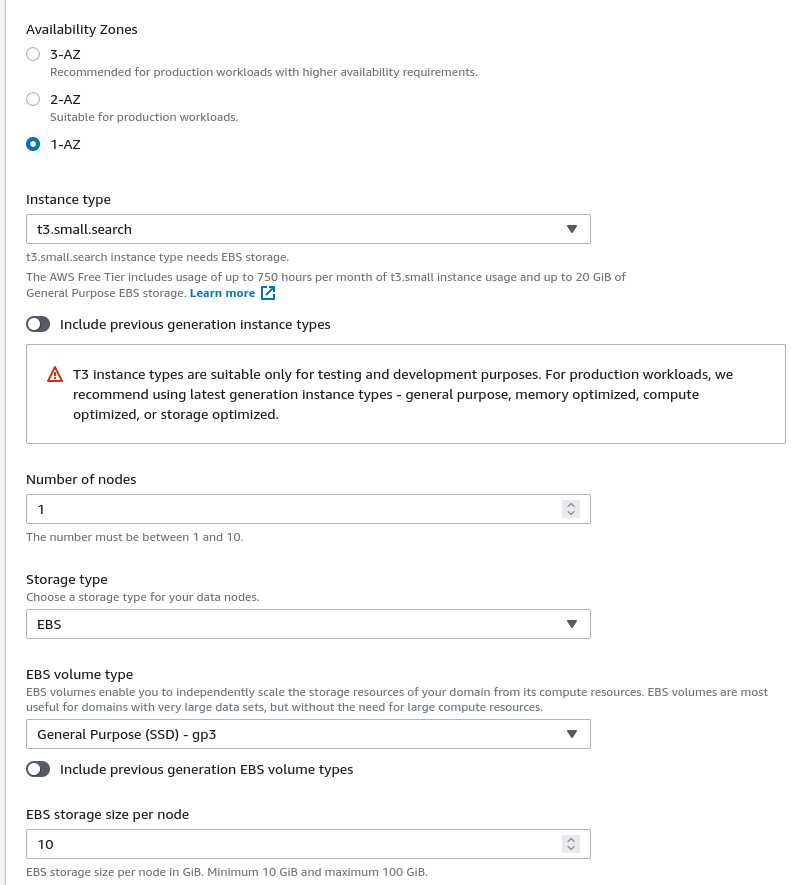
Scroll down until you get to the Network part. Usually, this is a bad idea without further tuning and control. However, for an experiment, it will be ok. We will use Public access for the network, which means we exposed our cluster endpoints to the Internet.
Because we exposed OpenSearch to the Internet, set up at least an admin user. I would recommend using IAM roles or certificates in a production environment. Let's call the user "hs_admin" and set up a password.
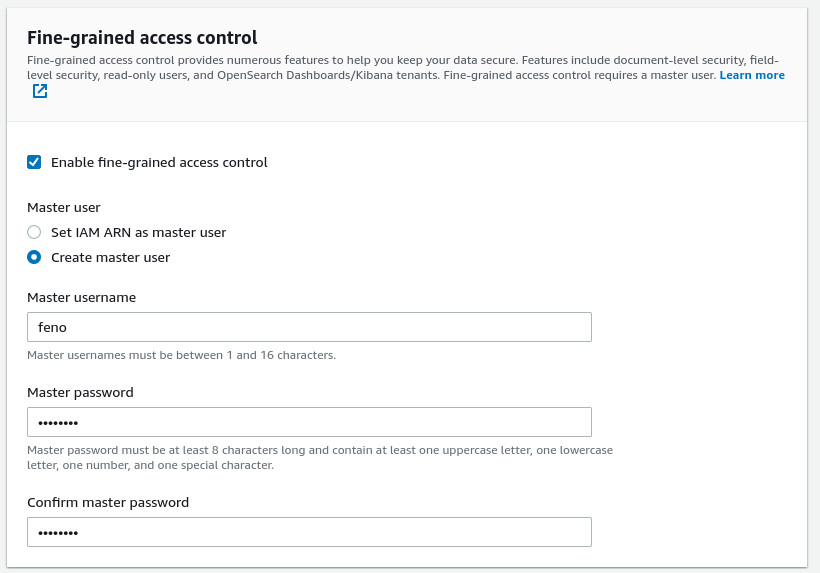
For a more straightforward setup and to avoid extensive configuration, let's turn off domain access policies and use just fine-grained access control. Avoid this on production.
Now hit the Create button on the bottom of the page and wait.
You'll see a page with loading information, like this one. It shows the steps of the cluster creation process. You will have to wait some minutes.
After some time, your cluster status will turn Green, like this:

Click on your recently created cluster: haystack.
You will see something like this:

The information that is important for us is the Domain endpoint, which is your cluster address:
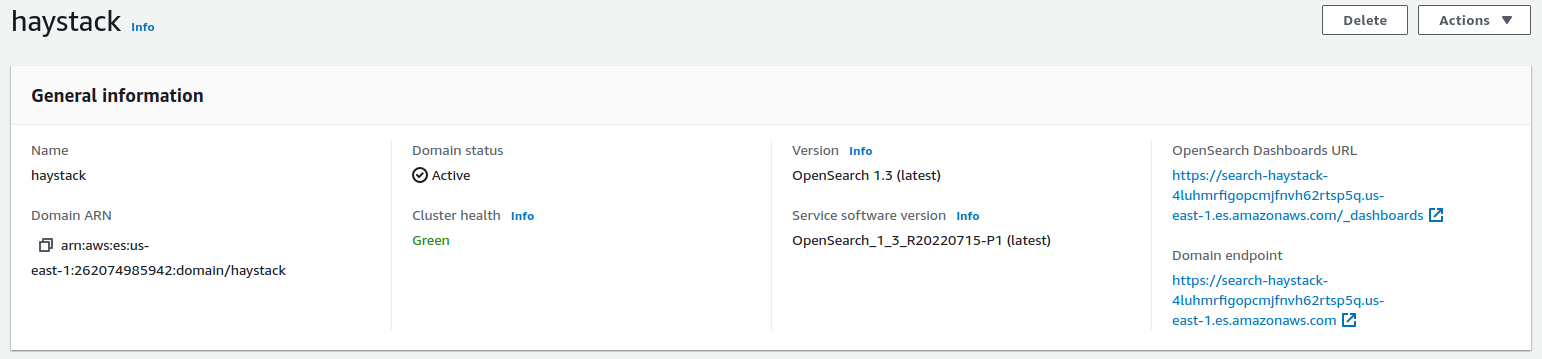
Here we end up with the creation of OpenSearch. Back to the code (finally).
Refactoring the application
The environments values
We must provide the authentication data to connect to our OpenSearch cluster. Putting this directly in code is a terrible decision. Never do it. It would be best if you used secret stores or environment variables.
We will now create a .env file in our project directory. You will fill it with the cluster address, the admin username, and the password. Remember to paste the server without the scheme(HTTPS or HTTP) and the port. These are extra parameters for Haystack OpenSearchDocumentStore.
OPENSEARCH_SERVER=search-haystack-4luhmrfigopcmjfnvh62rtsp5q.us-east-1.es.amazonaws.com
OPENSEARCH_SERVER_PORT=443
OPENSEARCH_USER=hs_admin
OPENSEARCH_PASSWORD=H2YsT2CkPa$$w0rd
We will install a library to help load environment variables during development.
pip install python-dotenv
On your app.py file, add.
from dotenv import load_dotenv
load_dotenv()
OPENSEARCH_SERVER = os.getenv("OPENSEARCH_SERVER")
OPENSEARCH_SERVER_PORT = os.getenv("OPENSEARCH_SERVER_PORT")
OPENSEARCH_USER = os.getenv("OPENSEARCH_USER")
OPENSEARCH_PASSWORD = os.getenv("OPENSEARCH_PASSWORD")
The variables from the environment will get loaded, but before, dotenv will check whether they are present or not. If not, it will use the .env data.
Initialize OpenSearchDocumentStore
With this in hand, we can now initialize our Haystack DocumentStore:
document_store = OpenSearchDocumentStore(
host=OPENSEARCH_SERVER,
port=OPENSEARCH_SERVER_PORT,
username=OPENSEARCH_USER,
password=OPENSEARCH_PASSWORD,
verify_certs=True
)
There are other parameters and ways of fine-tuning this initialization; you can read more here.
Data validation
Valid data in a REST endpoint is a need. We don't want anyone sending invalid data to our endpoints. So we will use data validation then.
Let's define a model for the requests made to our endpoints. First, we will send documents, which will be JSON documents with content and a name.
We will use pydantic for it. First, we will install it:
pip install pydantic
Then we will declare the new class:
class Document(BaseModel):
name: Optional[str] = None
content: str
Here there is an important point. Take care with naming classes on your project to avoid overwriting other classes. You can see I used Document. But then I remembered one of the most critical primitives in Haystack: Document. Like Labels and Answers, it's a pillar of it. So we will use an alias on the import like this:
from haystack.schema import Document as HaystackDocument
Let's keep the alias to avoid overwriting it while still getting in touch with the best NLP framework.
Add a document
We will define one way to add a document to our Document Store.
@app.post("/documents", status_code=201)
def save_document(document: Document):
new_doc= HaystackDocument(content=document.content, meta={"name": document.name})
document_store.write_documents([new_doc])
return {"id": new_doc.id}
We test the endpoint:
curl -X POST http://localhost:8000/documents/ -H 'Content-Type: application/json' -d '{"name":"My first Haystack document", "content":"Haystack is an open-source framework for building search systems that work intelligently over large document collections."}'
Wow, that was easy and fast! You should see this response:
{"id":"e41e6aeb0ae5965a912b672664e58b7c"}
It's the id that Haystack generated for your document. We are returning it.
Get a document
What if we want to get this document?
Let's build an endpoint to read a document by its id:
@app.get("/documents/{document_id}", status_code=200)
def get_document(document_id: str, response: Response):
document = document_store.get_document_by_id(document_id)
if document is None:
response.status_code = 404
return {"error": "Document not found"}
return document_store.get_document_by_id(document_id)
We are trying to get the document from Haystack OpenSearchDocumentStore; if there is not a document with this id, we will return a 404 HTTP response code with an error message. On the other hand, you will get a 200 HTTP response code with the document if it exists.
curl http://localhost:8000/documents/e41e6aeb0ae5965a912b672664e58b7c
Our response will have a bit more information than what we first sent to create the endpoint:
{"content":"Haystack is an open-source framework for building search systems that work intelligently over large document collections.","content_type":"text","id":"e41e6aeb0ae5965a912b672664e58b7c","meta":"name":"My first Haystack document"},"score":0.5312093733737563,"embedding":null}
The Document primitive of Haystack documentation is here. You will get a better understanding of each field there. By the way, the haystack documentation is pretty complete. Expend some time there. It will be a pleasant learning time.
Add more documents
curl -X POST http://localhost:8000/documents/ -H 'Content-Type: application/json' -d '{"name":"deepset Cloud", "content":"Build production-ready NLP services. deepset Cloud is a SaaS platform to build natural language processing applications."}'
curl -X POST http://localhost:8000/documents/ -H 'Content-Type: application/json' -d '{"name":"FastAPI", "content":"FastAPI is a modern, fast (high-performance), web framework for building APIs with Python 3.6+ based on standard Python type hints."}'
Get all documents
Now, what if we want to get all documents?
@app.get("/documents/", status_code=200)
def get_all_document(response: Response):
documents = document_store.get_all_documents()
if documents is None:
response.status_code = 404
return {"error": "Documents not found"}
return documents
We can test:
curl http://localhost:8000/documents/
This time our response will come with all the three documents we have added.
[{"content":"FastAPI is a modern, fast (high-performance), web framework for building APIs with Python 3.6+ based on standard Python type hints.","content_type":"text","id":"5209b538869b938ac94bf70fa0b09bd","meta":{"name":"FastAPI"},"score":null,"embedding":null},{"content":"Build production-ready NLP services. deepset Cloud is a SaaS platform to build natural language processing applications.","content_type":"text","id":"4985f3369c9c9c6a6ba179a004b0af72","meta":{"name":"deepset Cloud"},"score":null,"embedding":null},{"content":"Haystack is an open-source framework for building search systems that work intelligently over large document collections.","content_type":"text","id":"e41e6aeb0ae5965a912b672664e58b7c","meta":{"name":"My first haystack document"},"score":null,"embedding":null}]
There is one crucial thing that you must always pay attention. Never, never in any production return all entities into a single call, it may be on HTTP, GRPC, SQL query. Please, never do this! It's a horrible practice. Instead, you should use pagination techniques.
The example is shown just as a multi-document return because I knew only three documents existed. Imagine the damage you would cause to the servers if you had 10 million documents.
Querying the Document Store directly
We have handy nodes and pipelines on haystack. But you can run queries directly on your Document Store, even using custom DSL queries.
Let's set up a simple "search" endpoint.
@app.get("/documents/search/{query}", status_code=200)
def search_document(query: str, response: Response):
logging.debug(f"Searching for {query}")
documents = document_store.query(query)
return documents
We can call it by running:
curl http://localhost:8000/documents/search/saas
Our response will be:
[{"content":"Build production-ready NLP services. deepset Cloud is a SaaS platform to build natural language processing applications.","content_type":"text","id":"4985f3369c9c9c6a6ba179a004b0af72","meta":{"name":"deepset Cloud"},"score":0.508989096965447,"embedding":null}]
You must keep in mind two things for this elementary search and query:
- There are only three documents in our Document Store
- SaaS keyword is present in only one document.
- The query is concise and limited
If we had more documents with the keyword, the BM25 algorithm would help us with many answers and assign scores for each answer.
So remember, haystack is much more potent than this. We are using a tiny piece of the framework, mostly related to primitives and Document Stores. There are outstanding nodes to explore.
Furthermore, we could use a powerful filter on its haystack implementation. It would be something similar to:
filters = {
"$and": {
"type": {"$eq": "article"},
"date": {"$gte": "2015-01-01", "$lt": "2021-01-01"},
"rating": {"$gte": 3},
"$or": {
"genre": {"$in": ["economy", "politics"]},
"publisher": {"$eq": "nytimes"}
}
}
}
Note: This filter doesn't apply to our current application, it's just an example to understand its logic.
Extractive answer endpoint
We start by adding some imports:
from haystack.nodes import BM25Retriever, FARMReader
from haystack.pipelines import ExtractiveQAPipeline
We define a pydantic model:
class Query(BaseModel):
question: str
Then we add the endpoint:
@app.post("/documents/ask", status_code=200)
def ask_document(query: Query, response: Response):
model = "deepset/roberta-base-squad2"
retriever = BM25Retriever(document_store)
reader = FARMReader(model, use_gpu=True)
pipeline = ExtractiveQAPipeline(reader, retriever)
result = pipeline.run(query=query.question, params={"Retriever": {"top_k": 10}, "Reader": {"top_k": 1}})
answers = [x.to_dict() for x in result["answers"]]
return answers
Let's talk a bit about this endpoint.
First, we are defining which model we will use. The company behind haystack, deepset.ai, has made public some astonishing models on Hugging Face. You will find small, medium, and giant models. All of them have excellent quality. Please explore them. Oh, and don't forget to give them a like on Hugging Face.
Then we have set up a BM25Retriever, which will do a sparse search for us.
After that, we set up the FARMReader (our friends also developed FARM at deepset, it's an excellent framework for transfer learning).
We instantiate one of the ready-made pipelines. These pipelines fit the most common search patterns and chain haystack components. For example, the ExtractiveQAPipeline searches the OpenSearch document collection and extracts a piece of text (a span) that answer our question.
We call the endpoint:
curl -X POST http://localhost:8000/documents/ask -H 'Content-Type: application/json' -d '{"question":"What is deepset Cloud?"}'
Running this for the first time will take some time because haystack will download the model from the Internet. Depending on the model, deepset/roberta-base-squad2 is about 480 MB, and your connection speed can take less or more. But it's a one-time download, as long as you don't clean the virtual environment.
On your command line, you will get something like:
[{"answer":"a SaaS platform to build natural language processing applications","type":"extractive","score":0.6236580908298492,"context":"Build production-ready NLP services. deepset Cloud is a SaaS platform to build natural language processing applications.","offsets_in_document":[{"start":55,"end":120}],"offsets_in_context":[{"start":55,"end":120}],"document_id":"4985f3369c9c9c6a6ba179a004b0af72","meta":{"name":"deepset Cloud"}}]
I would like to emphasize some fields of the haystack Answer primitive:
answer: this is the piece of text that answers your submitted question. It's an extracted text (on this pipeline), which means it's equal to how the answer is present in the document.
score: it's the relevance of the answer.
offsets_in_document: where in the document (sent to OpenSearchDocumentStore) the answer is located.
document_id: the document id where the answer is present.
The end (for today)
Unfortunately, we have come to the end of this article. I want to share more, but keeping some topics separated now is better.
We have built a FastAPI application that provides endpoints for some sparse haystack retrievers. However, there is much more in Haystack:
- Pre-processing
- File converters
- Generator
- Summarizers
- Translators
- Rankers
- Classifiers
- ...
The list is yet extensive and covers almost all possible NLP search usage.
Useful Haystack links
- Open an issue here.
- Read the docs.
- Join the newsletter
- Join the Discord server.
I'm always around Haystack on Discord. So I'll be pleased to talk there.
